Steam Controller Auto-Charge: o robô de mesa que anda usando vibração e WASM
Conheça o Steam Controller Auto-Charge, projeto de código aberto que usa visão computacional OpenCV.js e haptics via WebHID para fazer o controle se recarregar sozinho.
Entenda o real significado de load average, estados de processos e consumo de memória no Linux com base nas métricas e detalhes técnicos do monitor htop.
No ecossistema de servidores Linux, poucas ferramentas de diagnóstico são tão populares e amplamente utilizadas quanto o htop e seu predecessor top. No entanto, o funcionamento interno dessas ferramentas e o real significado das métricas exibidas em suas interfaces continuam sendo um mistério para muitos desenvolvedores e administradores de sistemas. O especialista técnico Pēteris Ņikiforovs conduziu uma investigação profunda no sistema operacional Ubuntu Server 16.04 x64 para desmistificar o que cada elemento visual dessas ferramentas representa na prática. Essa análise revela que conceitos cotidianos, como a média de carga (load average), são interpretados de forma equivocada por muitos profissionais de TI, que associam erroneamente um load de 1.0 em uma máquina de dois núcleos a 50% de uso de CPU, ignorando as nuances do escalonamento de processos no kernel do Linux.
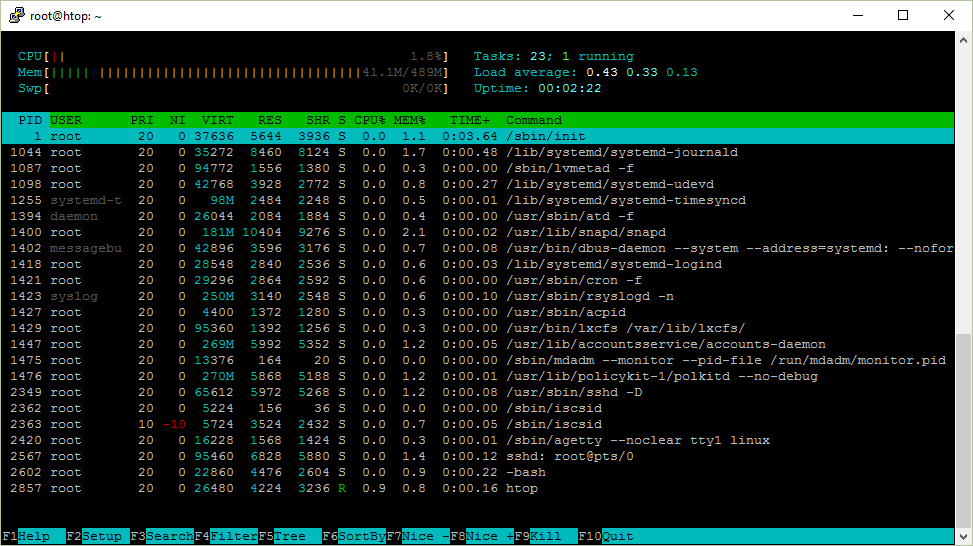
A jornada para compreender o monitor de processos começa pelo entendimento de métricas básicas de tempo, especificamente o indicador de uptime. Ao executar o tradicional comando uptime no console do Linux, o usuário recebe um resumo contendo informações cruciais sobre o estado da máquina, como no exemplo: 12:17:58 up 111 days, 31 min, 1 user, load average: 0.00, 0.01, 0.05. Esse utilitário, embora apresente as informações de forma limpa e estruturada para leitura humana, não realiza cálculos complexos em tempo de execução; em vez disso, ele atua simplesmente como um leitor de dados brutos que já são rastreados de forma contínua pelo sistema operacional Linux.
Toda a base factual exibida pelo comando de tempo de atividade reside no arquivo virtual /proc/uptime. Ao inspecionar o conteúdo desse arquivo, o administrador se depara com dois números decimais longos, como 9592411.58 9566042.33. O primeiro algarismo indica a quantidade total de segundos decorridos desde que o sistema operacional foi inicializado. O segundo número representa o tempo total, também mensurado em segundos, que a máquina passou em estado completamente ocioso (idle). Em servidores que contam com processadores de múltiplos núcleos físicos ou virtuais, esse segundo valor pode superar significativamente o tempo de atividade total do sistema, uma vez que se trata da soma do tempo ocioso acumulado de todas as CPUs concorrentes integradas ao hardware.
Para decifrar exatamente quais arquivos o utilitário do sistema acessa para obter tais dados, a investigação utilizou a ferramenta de depuração e auditoria de chamadas de sistema strace. Ao executar o comando de depuração direcionando as saídas de erro padrão para a saída padrão com a instrução strace uptime 2>&1 | grep open, foi possível capturar o fluxo de abertura de arquivos. O resultado revela que o utilitário interage diretamente com o arquivo de tempo de atividade /proc/uptime, com o arquivo de controle de logins de usuários em tempo real /var/run/utmp, e com o arquivo de acompanhamento de carga média /proc/loadavg. Uma alternativa simplificada de auditoria fornecida pelo autor é o uso direto do comando strace -e open uptime, que dispensa o encadeamento complexo de filtros no terminal de comandos do Linux.
O funcionamento detalhado do uptime e do htop revela como o Linux utiliza o sistema de arquivos procfs para comunicação de baixo nível entre o kernel e o espaço de usuário. O arquivo /proc/uptime serve como a fonte de verdade absoluta de tempo para o sistema. Quando o utilitário converte os segundos brutos em dias, horas e minutos amigáveis, ele poupa os administradores de realizarem divisões matemáticas manuais complexas em seus próprios scripts de monitoramento, ao mesmo tempo em que preserva a simplicidade do formato de ponto flutuante para a automação.
A dependência do arquivo de log /var/run/utmp ajuda o comando a mapear exatamente quantos usuários ativos estão interagindo com a máquina no momento da medição. Toda vez que uma sessão de terminal de comandos ou conexão SSH é estabelecida ou desfeita, esse arquivo de controle de estado dinâmico é atualizado instantaneamente. Ao correlacionar as informações de usuários conectados com o tempo acumulado no arquivo de medição de ociosidade, o Linux entrega uma visão sistêmica rápida, que serve como primeiro nível de diagnóstico para identificar se um hardware de servidor está subutilizado ou operando próximo do seu limite térmico de operação.
O segundo pilar crítico do monitoramento de desempenho é a média de carga, representada pelos três números do load average. Esse dado, essencial para a tomada de decisões em infraestruturas de servidores de hospedagem, é importado diretamente pelo kernel Linux a partir do arquivo virtual de sistema /proc/loadavg. Um exame manual desse arquivo por meio do utilitário cat /proc/loadavg retorna um registro estruturado em cinco blocos de informação distintos, como a string 0.00 0.01 0.03 1/120 1500. Os três primeiros valores decimais indicam as médias de carga do sistema correspondentes aos intervalos de 1 minuto, 5 minutos e 15 minutos, respectivamente, oferecendo um panorama histórico e imediato da demanda do hardware.
Os campos complementares do arquivo de carga trazem informações sobre o volume de tarefas e controle de identificação. Na representação fracionada 1/123 encontrada no arquivo de carga, o primeiro número aponta a quantidade de processos que estão atualmente em execução ou prontos para executar no processador, enquanto o segundo número indica o total absoluto de processos registrados na tabela global do sistema operacional. O último valor da linha, como o identificador 1566 ou 1500, registra o identificador numérico de processo (PID) alocado mais recentemente pelo kernel. O monitoramento desses números revela que a atribuição de PIDs ocorre de forma sequencial e incremental desde a inicialização do hardware, sendo que o processo mestre do sistema, o /sbin/init, sempre assume o histórico PID 1 logo no boot do sistema operacional.
Ao interagir com o terminal de comandos e disparar novas rotinas, o comportamento dessas tabelas é alterado de forma previsível e auditável. Por exemplo, ao lançar uma tarefa de espera em segundo plano através do comando sleep 10 &, o interpretador de comandos bash exibe imediatamente o número do job em colchetes seguido pelo PID gerado, como [1] 1567. Se o administrador abrir a interface do htop nesse exato momento e observar a existência de apenas um processo ativo, ele estará visualizando o próprio processo do htop em atividade na CPU, pois utilitários em modo de espera como o comando sleep 30 não realizam processamento real e são classificados em estado inativo ou dormente pelo agendador de tarefas do kernel.
O cenário se modifica drasticamente quando simulamos uma carga real de processamento no ambiente de testes. Ao executar o utilitário de geração de fluxos infinitos de dados aleatórios integrado ao Linux através da instrução de console cat /dev/urandom > /dev/null &, forçamos um ciclo ininterrupto de processamento matemático. A leitura subsequente do arquivo de status com o comando cat /proc/loadavg passa a exibir registros substanciais como 1.00 0.69 0.35 2/124 1679. Essa modificação no status confirma a existência de duas tarefas em execução concorrente no processador (o gerador de entropia e o próprio comando de leitura do arquivo de carga), refletindo a elevação imediata da média de carga do servidor no último minuto para o patamar de 1.00.
A concepção matemática que define esses números de carga é frequentemente simplificada como uma média aritmética tradicional do período de tempo analisado, o que constitui um equívoco conceitual grave. Na verdade, o kernel Linux utiliza uma fórmula matemática sofisticada denominada média móvel exponencialmente amortecida (exponentially damped moving average). Sob essa regra matemática, todos os valores registrados desde a inicialização do sistema influenciam as métricas exibidas, mas seus impactos decrescem de forma exponencial à medida que o tempo avança. No indicador de carga de 1 minuto, aproximadamente 63% da métrica é composta pela atividade real registrada nos últimos 60 segundos, enquanto os 37% restantes são derivados do histórico consolidado anterior do sistema.
Esta modelagem matemática explica os motivos pelos quais picos abruptos de utilização demoram para ser totalmente eliminados dos indicadores visuais do htop. Para simplificar a análise operacional, o autor adota uma regra prática: em uma máquina equipada com apenas uma CPU física, um processo que consuma exclusivamente poder de cálculo (CPU-bound) manterá a média de carga de 1 minuto estável em 1.00, o que equivale a 100% de utilização da capacidade daquele núcleo. Em contrapartida, caso o servidor disponha de uma arquitetura paralela equipada com 2 núcleos de processamento, uma carga contínua de 1.00 representará somente 50% de uso global da capacidade total do processador, pois o hardware de dois núcleos seria capaz de suportar um load average de 2.00 antes de atingir sua saturação total de escalonamento.
A estimativa de uso de CPU com base puramente no load average é tecnicamente imprecisa por um fator crucial de design do Linux: o cálculo de carga engloba também tarefas que se encontram em estado ininterrupto (uninterruptible state). Esse estado ocorre tipicamente quando um processo está bloqueado aguardando o retorno físico de operações lentas de leitura e gravação em disco rígido (I/O) ou trocas de pacotes em redes congestionadas. Como essas tarefas paralisadas não estão consumindo ciclos ativos de clock do processador, o sistema pode apresentar médias de carga elevadas mesmo com a CPU ociosa. Para isolar esses efeitos, o administrador pode utilizar o pacote sysstat por meio do comando de instalação sudo apt install sysstat -y, o que permite rodar o monitor instantâneo mpstat 1 para auditar as taxas de uso de usuário (%usr), sistema (%sys) e ociosidade (%idle) a cada segundo.
A natureza conceitual e o debate técnico sobre a utilidade dessa métrica são ilustrados pelo próprio código-fonte oficial do kernel Linux. Em uma inspeção no repositório público de desenvolvimento gerenciado por Linus Torvalds, especificamente no arquivo de sistema localizado no caminho estrutural kernel/sched/loadavg.c na versão de desenvolvimento v4.8 do kernel, encontra-se um comentário humorístico inserido pelos engenheiros que mantêm o agendador de tarefas do sistema operacional. O trecho documentado resume a visão pragmática da comunidade de desenvolvimento do kernel sobre o clássico indicador de performance:
/*
* kernel/sched/loadavg.c
*
* This file contains the magic bits required to compute the global loadavg
* figure. Its a silly number but people think its important. We go through
* great pains to make it work on big machines and tickless kernels.
*/
Ao analisar o painel superior direito do htop, nota-se que o monitor exibe a contagem de Tasks (tarefas) em vez de utilizar o rótulo convencional de Processes (processos). Esta decisão de terminologia ocorre por motivos de economia de espaço visual na tela do console e porque, sob a arquitetura interna do kernel do Linux, todos os fluxos de execução independentes e threads são gerenciados e referenciados de maneira genérica como tarefas. O operador do console pode gerenciar a visualização detalhada dessas estruturas pressionando a combinação de teclas Shift+H no teclado, ação que habilita ou oculta a listagem de threads adicionais pertencentes aos processos de usuário e altera a linha de controle do cabeçalho para marcações como Tasks: 23, 10 thr.
Outro recurso valioso de visibilidade de baixo nível é a exibição de threads internas ativas pertencentes ao próprio kernel Linux. Ao utilizar o atalho de teclado Shift+K, o monitor dinâmico do htop passa a incluir ou ocultar a atividade de controle do sistema, atualizando as métricas descritivas para formatos como Tasks: 23, 40 kthr. Para que os administradores possam analisar o comportamento individual de cada tarefa ativa, as colunas do monitor de recursos exibem códigos de caracteres padronizados que revelam o estado operacional atual de cada processo de software, fornecendo informações essenciais sobre a eficiência do processamento do servidor.
O ciclo de vida das tarefas no Linux é dividido em seis estados fundamentais representados por letras específicas em ferramentas de monitoramento. O caractere R (running or runnable) indica que o processo está em execução física imediata nos registradores da CPU ou aguardando sua vez na fila de agendamento (run queue). O caractere S (interruptible sleep) aponta que a tarefa está em repouso interrompível, aguardando pacientemente que um evento externo, sinal de rede ou interrupção de hardware finalize para que ela possa retomar seu fluxo de processamento. A letra D (uninterruptible sleep) representa processos suspensos de forma ininterruptível, normalmente bloqueados enquanto aguardam respostas diretas de leitura ou gravação de subsistemas de disco físico de I/O de alta prioridade.
Os estados restantes descrevem rotinas de término, depuração e controle de fluxo do terminal. O caractere Z (defunct ou zombie) descreve um processo zumbi, ou seja, uma tarefa que foi finalizada fisicamente no sistema operacional, mas cuja tabela de recursos e código de saída ainda não foram recolhidos pelo processo pai responsável por sua criação. O caractere T (stopped by job control) indica que o processo foi intencionalmente paralisado por meio de sinais de controle gerados no console do terminal de comandos. Por fim, o caractere t (stopped by debugger) indica que a tarefa em questão teve sua execução temporariamente interrompida e congelada por uma ferramenta externa de depuração e diagnóstico de software durante uma análise de código.
Toda a infraestrutura de dados consumida pelas interfaces gráficas do htop e do top é extraída do pseudo-sistema de arquivos denominado procfs, mapeado por padrão no caminho raiz de diretórios /proc/. Esse diretório especial não armazena arquivos persistentes em mídias de armazenamento físicas, mas atua como um barramento virtual dinâmico criado pelo kernel Linux para expor informações de baixo nível sobre os processos ativos direto para o espaço de usuário (userland). Ao inspecionar o subdiretório associado a um PID em execução, como o caminho /proc/12503, o administrador tem acesso imediato a arquivos de dados brutos cruciais como cmdline, cwd, exe, limits, maps e status.
O arquivo de texto especial localizado no caminho relativo /proc/<pid>/cmdline armazena a string de comando exata e todos os parâmetros de execução fornecidos no momento em que a tarefa foi inicializada no terminal. Devido às restrições de formatação estrutural interna do kernel do Linux, esses comandos e argumentos de console são gravados separados pelo caractere de byte nulo (identificado pela representação \0). Para transformar esses dados brutos em uma estrutura legível para operadores humanos, o administrador de sistemas pode utilizar utilitários clássicos de filtragem, rodando o comando de substituição tr '\0' '\n' < /proc/12503/cmdline ou empregando o binário de varredura de strings imprimíveis strings /proc/12503/cmdline.
Outros componentes críticos contidos no subdiretório do processo incluem links simbólicos dinâmicos que funcionam como ponteiros de infraestrutura. O link simbólico nomeado cwd aponta diretamente para o diretório de trabalho atual do processo (current working directory), facilitando a auditoria de atividades de scripts em execução, enquanto o link simbólico exe atua como um ponteiro físico para o arquivo binário original que foi executado (por exemplo, apontando para o utilitário do sistema /bin/sleep). É precisamente por meio da varredura automatizada e sistemática desses arquivos estruturados dentro de diretórios como /proc/12503/cwd que os monitores de recursos constroem as colunas dinâmicas exibidas na tela do usuário.
A árvore hierárquica que define a relação entre processos filhos e pais pode ser ativada na interface gráfica do htop pressionando a tecla de função F5, revelando o fluxo de ramificações do sistema operacional de forma gráfica. Em consoles convencionais sem suporte visual de monitoramento dinâmico, os operadores de sistemas Linux podem atingir essa mesma visibilidade detalhada executando o utilitário tradicional ps f, que recua as linhas de comando filhas usando recuos e caracteres de barra no terminal, ou acionando a ferramenta de terminal especializada pstree -a, que exibe toda a cadeia de controle em formato de grafo de conexões de software a partir do processo primordial do sistema, o inicializador init.
A criação de novos processos filhos a partir de interpretadores de comando clássicos como o bash envolve um mecanismo de execução em duas etapas distintas chamado de fork e exec. Inicialmente, o shell ativo executa a chamada de sistema (system call) denominada fork, que clona de forma exata o processo pai na memória RAM da máquina, herdando suas credenciais de usuário e variáveis de ambiente. Na sequência de execução imediata, a réplica aciona a chamada de sistema exec (ou execve), que sobrepõe a área de memória temporária do clone com as instruções de máquina e recursos do novo arquivo binário executável desejado (como o utilitário de data e hora do sistema /bin/date), liberando o fluxo de controle enquanto o pai aguarda o encerramento da rotina filha.
Para além do controle de processamento e das árvores de dependência, as colunas do htop expõem métricas complexas de consumo de memória RAM do sistema sob as siglas VIRT, RES, SHR e MEM%. A coluna VIRT (Virtual Image), por vezes identificada como VSZ (Virtual Size), expressa a quantidade total de espaço de endereçamento virtual alocado e acessado pelo processo de software. Isso inclui recursos diversos mapeados na memória que podem ainda não ter sido gravados fisicamente na RAM do servidor, como arquivos temporários alocados na partição de troca swap do disco, bibliotecas compartilhadas de sistema e páginas de dados em buffers de espera.
O consumo real e tangível da memória física da máquina é medido com precisão milimétrica por meio da coluna RES (Resident Size), referenciada em outras ferramentas de diagnóstico técnico como RSS (Resident Set Size). Esta métrica fundamental do sistema operacional Linux reporta exclusivamente a quantidade exata de memória física RAM que está sendo de fato consumida pelo processo específico sem contabilizar áreas temporárias de swap, sendo o principal parâmetro de referência para a identificação de vazamentos de recursos de memória (memory leaks) em servidores de produção. A coluna de compartilhamento SHR (Shared Memory Size) rastreia os recursos comuns reutilizáveis por outras aplicações do ecossistema, enquanto a coluna percentual MEM% estabelece a relação aritmética simples entre o volume de memória residente do processo (RES) e o volume total de RAM física disponível no hardware.
Conheça o Steam Controller Auto-Charge, projeto de código aberto que usa visão computacional OpenCV.js e haptics via WebHID para fazer o controle se recarregar sozinho.
O desenvolvedor Caue Napier abriu o código do TownSquare no GitHub, permitindo integrar chats efêmeros com bonecos de palito em tempo real em qualquer site.
Reflection AI usará o supercomputador Colossus 2 da SpaceX em um acordo de até US$ 6,3 bilhões focado em chips Nvidia GB300 para treinar modelos abertos.